BLIP model | paper summary
This is a quick summary of the BLIP : Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding & Generation model
Paper overview
The problem 📝
- Data from the internet is dirty and lacking
- Alt property in images is sometimes filled with bad captions
- Clip based models are trained on this data
General ideas 💡
- Grouping best practices from the multimodal field into a single model
- pre-trained on multiple tasks
- Image captioning
- Visual question & answering
- Image-text retrieval (neural search)
- Bootstrapping method – 2 steps (more info below)
- Filter – distinguish good from bad data (based on CapFilt paper)
- Clear bad pairs from the dataset (which is from the internet)
- Captioner – generation
- Filter – distinguish good from bad data (based on CapFilt paper)
Background: Architectures in this field 🏭
- Encoder architecture (e.g. CLIP)
- Image/text pairs – output match
- Not straight-forward for generation tasks (VQGANS, diffusion etc)
- Encoder-decoder
- train the model to produce text from an input image
- not adopted for image-text retrieval
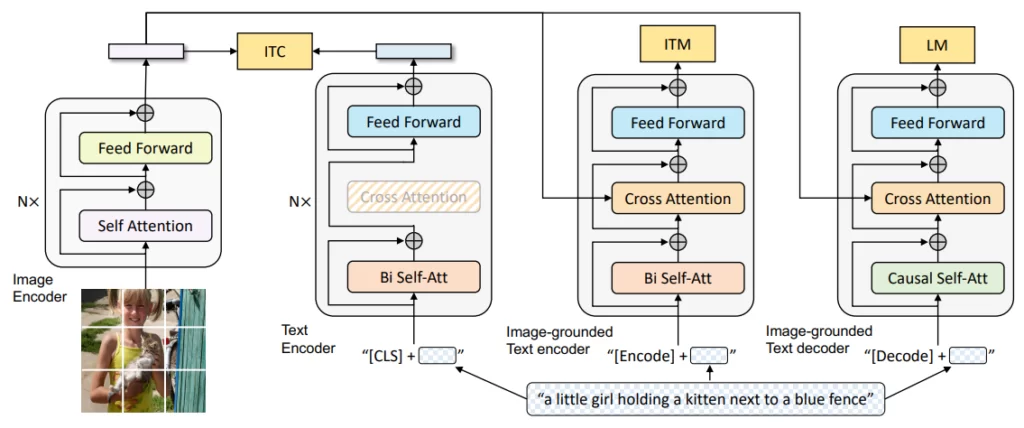
BLIP architecture 📸
- Encoders ingest the raw text/image and output embeddings
- Image: ViT image encoder
- Text:
- Unimodel encoder – text encoder similar to BERT
- Image-grounded text encoder – considers also the output of the ViT image encoder
- Produce a joint representation of the text and image
- Image-grounder text decoder – generates text while using the output of the ViT image encoder
Loss functions
- ITM – matching loss
- Whether a pair of images and text are related or not (matched/unmatched)
- Uses a “hard negative mining” – picks high negative examples during training
- LM – language modeling loss
- Cross entropy loss – maximize the likelihood of the text in autoregressive manner
- ITC – image-text contrastive loss
- align the feature space between the visual and textual encoder
Bootstrapping method
Flow
- Train the model with the noisy data
- Use coco dataset to finetune a filter and a captioner
- The coco captions considered high quality and extensive
- Finetune different parts of the architecture separately
- Produce captions and pass them through the filter
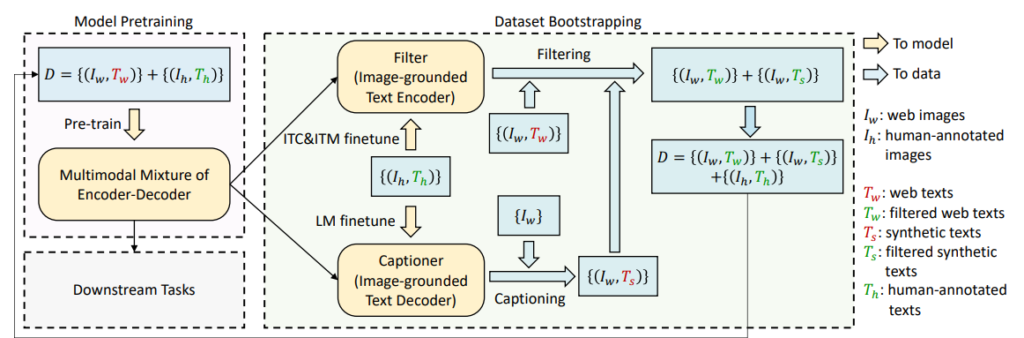
Captioner
- Captioner generates synthetic captions
Filter
- The filter is removing noisy captions from both the original texts from the HTML, and also from the synthetic texts made by the captioner
- Pros – Eventually produce much more reliable dataset
- Cons – restrict the dataset to learn on unknown domains
{kind=link}
{kind=link}